J’ai fait un score avec Datacadabra… Quelle différence ?

Vous avez une licence Datacadabra ! C’est bien, c’est même très bien. Vous avez compris que la data est en enjeu majeur pour votre activité, que vous allez pouvoir optimiser vos actions et que vos clients réclament une relation personnalisée. Et… cerise sur le gâteau, vous avez choisi la solution idéale pour répondre à ces enjeux, gagner en autonomie et donc en réactivité (non, je n’ai pas de parti pris 🙄).
Aujourd’hui, vous voulez vous lancer dans votre premier score en mode solo (ou avec accompagnement si besoin, n’hésitez pas, nous sommes là pour ça !)
L’objectif de cette Newsletter va être de vous donner les clés pour comprendre, apprendre et maîtriser le scoring via datacadabra.
Qu’est-ce qu’un score ?
La question peut sembler bête, mais comme le dit le dicton, « les questions idiotes sont celles qu’on ne pose pas ».
Un score permet de mettre en avant le caractère prédictif d’un évènement, mais pas n’importe comment. Un évènement pour lequel la réponse sera oui ou non.
Quelques exemples :
- Je ne peux pas répondre à la question « quelle sera la météo demain ? » mais je peux répondre à la question « est-ce que le ciel sera ensoleillé demain ? » (ou nuageux 😉)
- Je ne peux pas répondre à la question « combien de pulls je vais vendre demain ? » mais je peux répondre à la question « est-ce que je vais vendre 80% de mes pulls en rayon ? » voire (et c’est là que les experts CRM entrent en jeu) « est-ce que ce client va m’acheter ce pull ? »
- Je ne peux pas répondre à la question « quel produit proposer à mon client », mais je peux répondre à la question « est-ce que ce client va acheter ce produit ? ».
J’arrête les exemples, je pense que vous avez compris. L’important, c’est de comprendre que le score répond par ‘oui’ ou ‘non’… et ça peut, par moment, demander une petite gymnastique intellectuelle.
Bien évidemment, le score va vous donner une probabilité de réalisation d’un évènement (il y a 80% de chance que ce client achète ce produit).
OK, mais comment ça marche ?
La première chose à savoir, c’est qu’un score se base sur des données historiques. On ne part pas de rien. Il faut que l’évènement se soit déjà produit et avoir une base de données permettant de justifier la réalisation de cet évènement.
Nous allons essayer d’illustrer la chose avec des chats. Parce que les chats, c’est mignon (il paraît) et que ça se partage bien sur les réseaux (c’est pour notre visibilité 😉).
Vous voulez vous offrir un chat. Mais vous voulez un chat noir.

La première possibilité, et là, le scoring ne peut rien pour vous, est de réserver un chat, d’une portée de chats de l’ami d’un ami, que vous ne connaissez pas, dont vous ne connaissez rien des chats… et là, c’est la grande loterie…
Maintenant, si votre ami vous dit qu’il a un chat des mêmes parents chats, et que celui-ci est noir, où a des tâches noires, vous savez que vous avez une chance d’obtenir un chat noir.
Et si maintenant, on vous dit que le « papa chat » est noir et la « maman chatte » est rousse, vous augmentez encore vos chances d’avoir un chat noir.
En supposant que vous passiez par un élevage de chat, avec plusieurs combinaisons de ‘parents chats’ possibles, votre scoring sera donc défini ainsi :
Cible = 1 si le chaton est noir, 0 sinon
Variables explicatives :
L’un des parents est noir = 1 si oui, 0 si non
L’un des frères/sœurs est noir = 1 si oui, 0 si non
Vous aurez donc une base de données qui ressemble à ceci :
(Bien évidemment, tout ceci n’est que fictif, c’est pour illustrer l’exemple)
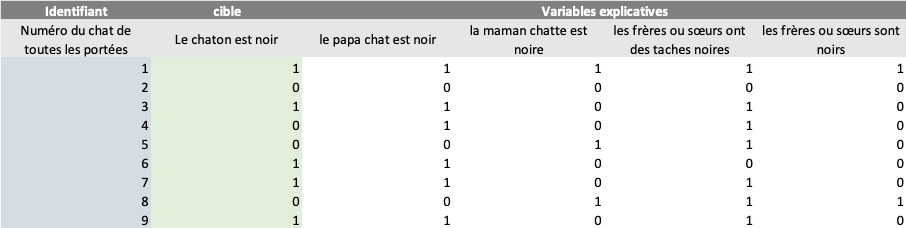
J’ai volontairement choisi des variables binaires (qui prennent la valeur 0 ou 1) pour illustrer l’exemple mais les variables explicatives peuvent être nominales (couleur du chat = noir, roux, noir et roux…) ou numériques. Datacadabra se chargera de transformer ces variables en variables binaires.
Votre base de données est ainsi prête pour être intégrée dans datacadabra et calculer votre probabilité d’obtenir un chat noir (dans la réalité, il faut intégrer au modèle un maximum de données pour être certain de pouvoir expliquer la couleur du chat).
Premier cas d’école
Normalement, si ma prose est suffisamment claire, à ce stade, vous avez compris ce qu’est un score et comment ça fonctionne.
Maintenant, vos données sont dans Datacadabra, vous avez lancé votre score et… et… Aïe Aïe Aïe !!! « Je fais quoi maintenant ??? »
Maintenant, Il faut analyser les sorties de datacadabra ! Elles sont commentées, c’est rassurant, mais vous souhaitez en comprendre davantage.
Nous allons continuer avec des chats. Cette fois-ci, ce que vous souhaitez, c’est avoir un chat mignon, pour faire des câlins, et pas un chat qui griffe et qui mord.
Vous avez pu récupérer la base de données de l’élevage avec l’historique de toutes leurs portées (ici, 20 chatons) dont ¼ ont eu un comportement doux et agréable.
(Plein de petit chatons… 😍)

Cette base de données est assez riche :
Cible : Le chat est mignon = 1 sinon 0
Variables explicatives :
Le papa est docile (binaire) = 1 sinon 0
La maman est docile (binaire) = 1 sinon 0
Longueur des canines du papa (numérique)
Longueur des canines de la maman (numérique)
Longueur des poils du papa (numérique)
Longueur des poils de la maman (numérique)
Couleur du pelage du papa (nominale)
Couleur du pelage de la maman (nominale)
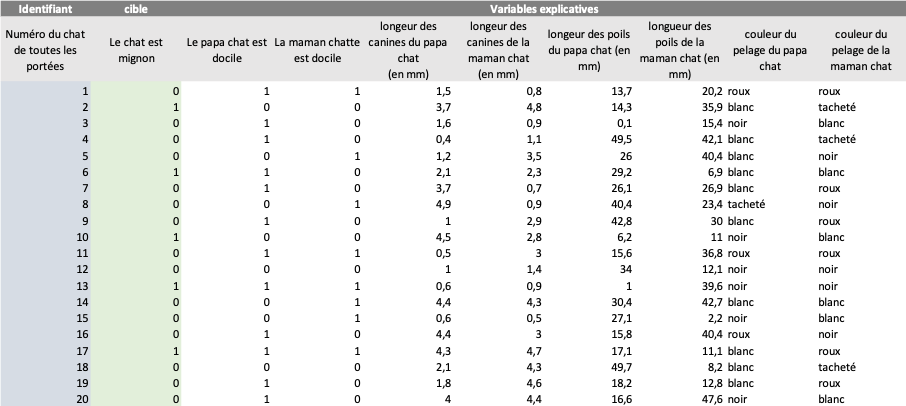
Je vous passe les étapes intermédiaires dans datacadabra, vous avez les données dans votre datamart, et en quelques clics, votre score est lancé, et il ne reste plus qu’à interpréter les résultats (et c’est d’ailleurs tout l’objet de cette newsletter).
Dans les parties suivantes, nous allons nous focaliser sur l’analyse des sorties Datacadabra.
Un peu de culture générale
Alors oui, cette partie ne reflète pas de la culture générale, mais bien d’une culture spécifique au scoring, mais c’est toujours bon à savoir.
Un score, c’est une fonction (ici, une régression logistique pour être précis).
La formule, peut sembler un peu complexe :
S = Note de score
Variables explicatives = X1, X2, …, Xn
Coefficient du modèle : A1, A2, …, An
α = constante du modèle (car tout modèle à une constante)
Les coefficients du modèle sont calculés par datacadabra (c’est là où l’analyse de corrélation de variable prend tout son sens, mais pas la peine d’entrer dans le détail)
A la fin, nous obtenons une formule qui ressemble à ça :
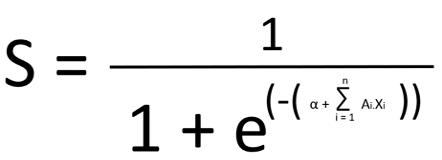
Pas très sexy tout ça, mais ne vous en faites pas, les outils de nos jours font ça tout seul 😉.
Ce qui est intéressant, ça n’est pas la formule, mais sa représentation graphique :
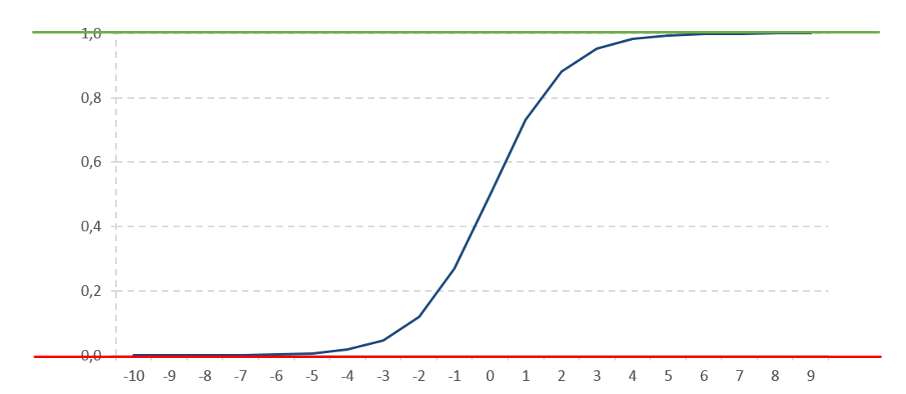
Cette fonction prend des valeurs (quel que soit X) comprise entre 0 et 1… ou, si vous me suivez, entre une probabilité égale à 0 ou une probabilité égale à 100%. (pour la petite histoire, cette fonction est infinie, cela veut dire qu’elle ne touche jamais, ni le 0, ni le 1… mais c’est du détail).
La combinaison de toutes vos variables explicatives vous placera donc sur un point de cette courbe plus ou moins proche du 1 en fonction de la probabilité de réalisation de votre évènement.
Je ne vais pas plus loin sur la technique, et évidemment, si cette partie vous semble encore nébuleuse, ne vous en faîtes pas, elle n’est pas essentielle pour la suite.
1ère sortie importante de datacadabra : Onglet 2. Coefficients du modèle
Il s’agit du premier onglet sur lequel vous devez vous attarder.
Cet onglet vous donne les variables explicatives de votre modèle, C’est-à-dire celles qui ont un impact sur la prévision (4 ou 5 en général // plus l’évènement est difficile à prévoir, plus il y aura de variables).

Ici, le fait que la maman chatte soit docile augmente fortement la probabilité d’avoir un chaton mignon. Au contraire, si le papa chat à des canines de plus de 2,2mm de longueur, la probabilité d’avoir un chat mignon diminue.
Les barres vertes et rouges sur le côté permettent d’avoir une visualisation rapide de l’impact des variables sur le modèle.
Attention :
Dans notre exemple, les variables sont compréhensibles, mais il se peut que vous ne compreniez pas pourquoi une variable entre dans le modèle. C’est la magie de la data (et surtout de la corrélation de variables). Il faut bien garder en tête, que même si votre base de données est bien fournie en variables, vous n’avez pas toutes les explications. Les variables exogènes (en dehors de votre écosystème) ont également un impact fort sur vos prévisions. Un exemple connu, c’est la météo. Historiquement, nous n’enregistrions pas la météo dans les bases. Mais chaque mois étant différent en termes de météo, les prévisions prenaient en compte des saisonnalités mensuelles. C’est ainsi que les maillots de bain arrivent en mai/juin dans les magasins et les pulls fin août/début septembre.
En gros, une variable peut en cacher une autre.
A ce stade, il y a déjà un cas de figure où vous pouvez rejeter le modèle.
Si la représentation graphique de vos variables explicatives ressemble à ça :
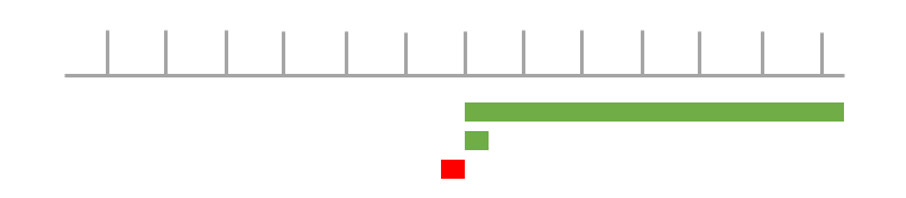
Ici, vous avez une variable, qui a elle seule, explique quasiment la totalité de la prévision. Cela signifie que cette variable est trop corrélée avec la variable cible. C’est comme si, dans vos variables explicatives, vous aviez une variable qui vous dit si oui ou non, la maman chat a toujours donné naissance à des chatons (et pas de chiots…).
Dans ce cas, il faut relancer le score en excluant cette variable des variables explicatives du modèle.
Onglet 3. Courbe de lift
C’est cet onglet qui vous permettra de lire le caractère prédictif de votre modèle. C’est d’ailleurs en voulant expliquer la courbe de lift que j’ai eu l’idée de cet article. Avec mes 15 ans de data (sans compter mes études), ça me paraissait tellement simple à comprendre et ça s’est avéré vraiment complexe à expliquer (certains me diront que si on ne sait pas expliquer simplement les choses, c’est qu’on ne les comprend pas soi-même …)
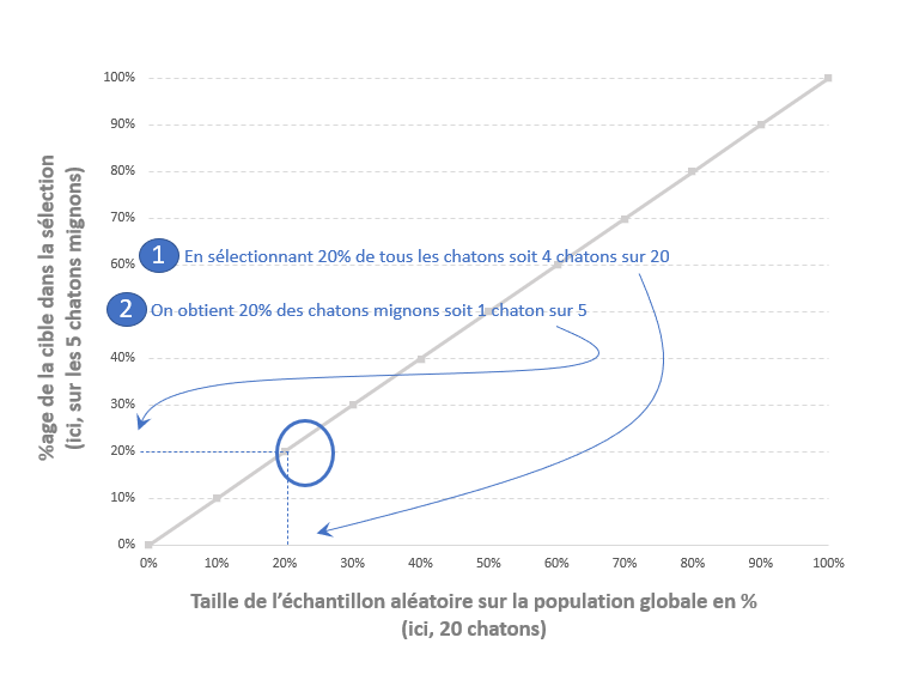
Si on reprend notre cas d’école, nous avons 20 chatons, dont 25% sont des chatons mignons (qu’on peut câliner, chouchouter sans perdre un doigt). Soit 5 chatons mignons et 15 chatons à éviter.
Si vous décider d’en sélectionner 20%, de façon aléatoire, la statistique vous amènera à sélectionner 20% des chatons mignons.
En gros, sur le global, vous avez 5 chatons mignons, et 15 chatons pas très sympas, et bien, sur une sélection à 20% en aléatoire, vous aurez 3 chatons pas très sympas (20% de 15 chatons) et 1 chaton mignon (20% de 5 chatons). La proportion de 25% de chatons mignons reste respectées dans une sélection aléatoire.
De ce fait, la courbe de lift d’une sélection aléatoire ressemble à ça :
Comme nous l’avons vu, plus, haut, le score va vous donner, pour chaque chaton, une probabilité d’être mignon.
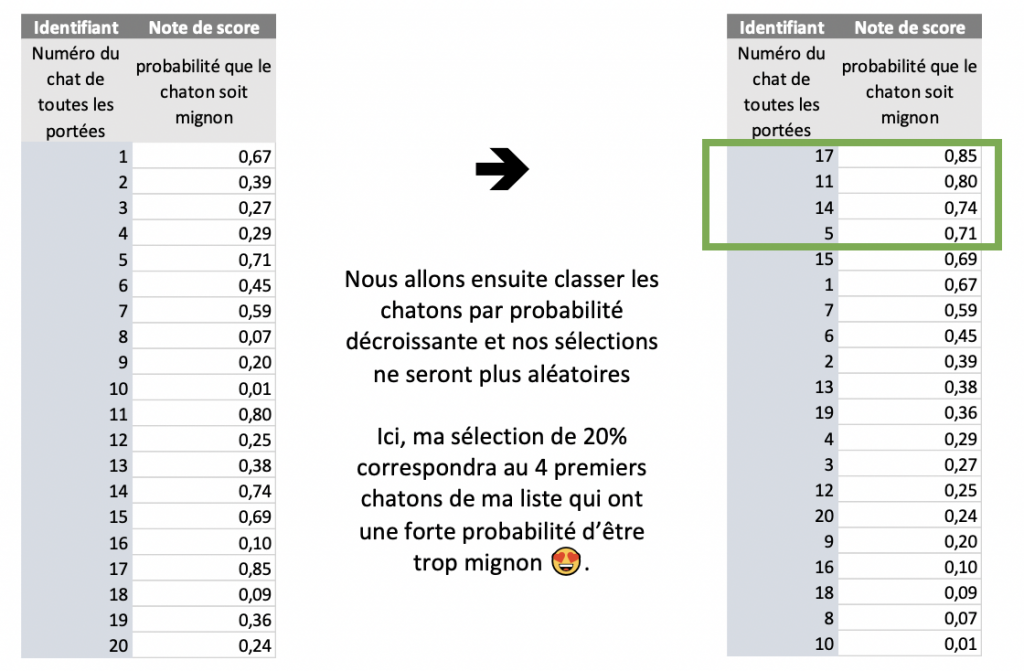
Pour tracer le courbe de lift, nous allons appliquer le score à nos données historiques et vérifier la part de « bonnes prédictions ».
Et si le modèle est « bon », en général, on obtient une courbe de ce type :
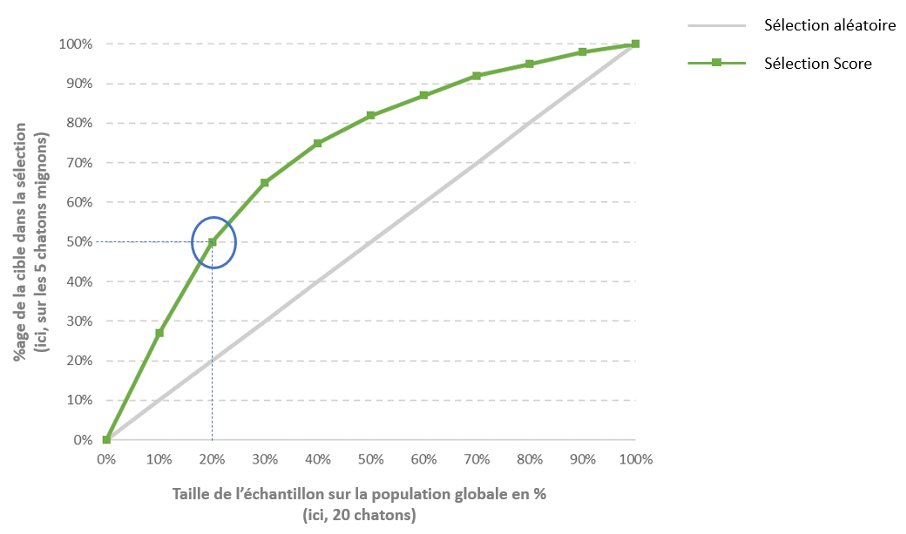
En sélectionnant les 20% de chatons les mieux scorés, on obtient 50% des chatons mignons. Autrement dit, en sélectionnant les 4 chatons les mieux scorés, on obtient entre 2 et 3 chatons mignons (2.5 précisément, mais on ne découpe pas des chatons… sinon, ils ne sont plus vraiment mignons 😂). Alors qu’avec une sélection aléatoire, on en obtenait 1. Le score permet donc d’optimiser nos chances de sélectionner un chaton mignon.
Ici aussi, certaines courbes peuvent vous amener à rejeter le modèle :
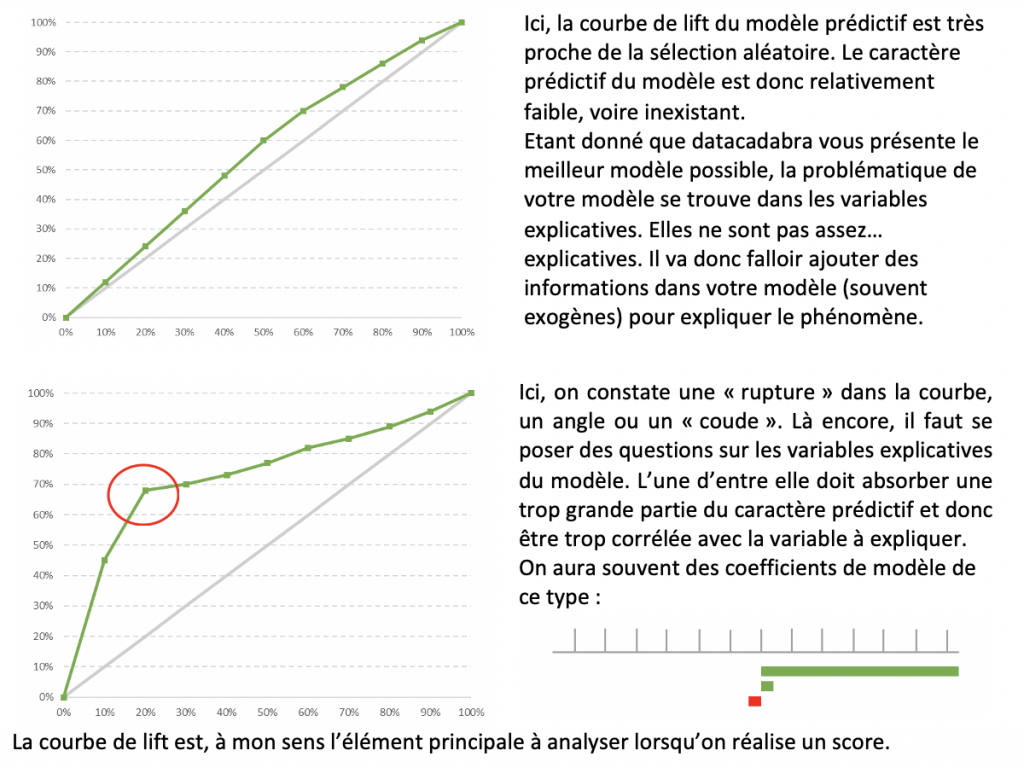
Avec ces éléments, vous avez ce qu’il vous faut pour valider votre score. Des variables explicatives décorrélées de la cible, une courbe de lift validant le caractère prédictif du modèle. La prochaine étape, vous servira à déterminer votre ciblage.
Onglet 4. Courbe de rendement
La courbe de rendement permet d’identifier les « faux positifs » par tranche de score de votre modèle.
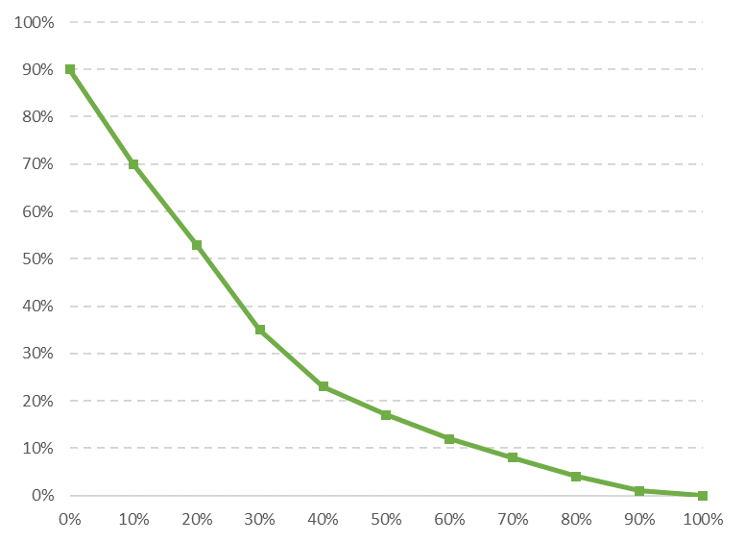
Pour faire simple, dans cet exemple de courbe, sur la première tranche, vous aurez 90% de la cible présente. Si on reprend notre exemple de chat, en sélectionnant les 10% de chats les mieux scorés (soit 2 chats), 90% d’entre eux seront des chats mignons (0.9 chat).
Personnellement, je m’en sers pour optimiser mes actions. Quand la tranche de score a un pourcentage de positif inférieur au vrai taux de positif, cela ne vaut plus la peine de se battre. Ici, dans l’exemple des chats, je ciblerais les 4 premières tranches (voire 3…). Les tranches suivantes me sortiront moins de chats mignons qu’une sélection aléatoire (car une sélection aléatoire me donnera 25% de chatons mignons par tranche).
En fonction de ce qu’on score, on peut :
- exclure les premières tranches = dans l’utilisation d’un score de réactivation par exemple, où il ne serait pas utile de se battre pour des clients pour lesquels nous sommes sûrs qu’ils reviendront naturellement.
- Exclure les dernières tranches pour exclure les causes perdues, ou les clients qui ont peu de chance de répondre à notre ciblage…
Tout dépend maintenant de ce que voulez faire…
Voilà, j’en ai fini avec cet article, certes, un peu long, mais qui, je l’espère, vous sera utile.
En résumé, pour vous lancer dans le scoring, il vous faut :
- Bien cerner votre problématique = bien formuler votre question, être précis… il vaut mieux réaliser plusieurs scores très précis plutôt que d’essayer de faire un score générique)
- Avoir une idée de ce que vous voulez en faire = est-ce que je vais vouloir cibler ces clients, les exclure ?
Et laisser datacadabra faire le reste 😉
Bien évidemment, si vous êtes datascientist, vous trouverez cet article inutile, peut-être même que vous trouverez mes raccourcis un peu grossiers. Mais vous n’êtes pas vraiment la cible de ces explications.
Et surtout, n’hésitez pas, Datacadabra est toujours là pour vous accompagner.
N’hésitez pas à demander une démo !
